MindMap Gallery Machine learning algorithm linear regression decision tree notes self-study mind map
Machine learning algorithm linear regression decision tree notes self-study mind map
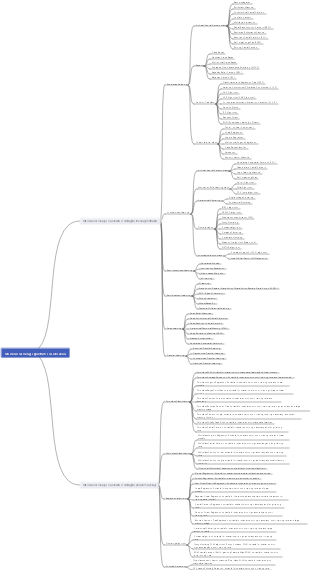
Machine learning algorithm linear regression decision number notes self-study complete sharing! The content covers K-nearest neighbor algorithm, linear regression, logistic regression, decision tree, ensemble learning and clustering.
Edited at 2023-02-25 09:44:36- New Employee First - week Onboarding Plan
Mappa mentale per il piano di inserimento dei nuovi dipendenti nella prima settimana. Strutturata per giorni: Giorno 1 – benvenuto, configurazione strumenti, presentazione team. Secondo giorno – formazione su policy aziendali e obiettivi del ruolo. Terzo giorno – affiancamento e primi task guidati. Il quarto giorno – riunioni con dipartimenti chiave e feedback intermedio. Il quinto giorno – revisione settimanale, definizione obiettivi a breve termine e integrazione culturale.
- Analisi del campo di allenamento inglese
Mappa mentale per l’analisi della formazione francese ai Mondiali 2026. Punti chiave: attacco stellare guidato da Mbappé, con triplice minaccia (profondità, taglio, sponda). Criticità: centrocampo poco creativo – la costruzione offensiva dipende dagli attaccanti che arretrano. Difesa solida (Upamecano, Saliba, Koundé). Portiere Maignan. Variabili: gestione infortuni e condizione fisica dei big. Ideale per scout, giornalisti e tifosi.
- Analisi della lineup francese
Mappa mentale per l’analisi della formazione francese ai Mondiali 2026. Punti chiave: attacco stellare guidato da Mbappé, con triplice minaccia (profondità, taglio, sponda). Criticità: centrocampo poco creativo – la costruzione offensiva dipende dagli attaccanti che arretrano. Difesa solida (Upamecano, Saliba, Koundé). Portiere Maignan. Variabili: gestione infortuni e condizione fisica dei big. Ideale per scout, giornalisti e tifosi.
Machine learning algorithm linear regression decision tree notes self-study mind map
- New Employee First - week Onboarding Plan
Mappa mentale per il piano di inserimento dei nuovi dipendenti nella prima settimana. Strutturata per giorni: Giorno 1 – benvenuto, configurazione strumenti, presentazione team. Secondo giorno – formazione su policy aziendali e obiettivi del ruolo. Terzo giorno – affiancamento e primi task guidati. Il quarto giorno – riunioni con dipartimenti chiave e feedback intermedio. Il quinto giorno – revisione settimanale, definizione obiettivi a breve termine e integrazione culturale.
- Analisi del campo di allenamento inglese
Mappa mentale per l’analisi della formazione francese ai Mondiali 2026. Punti chiave: attacco stellare guidato da Mbappé, con triplice minaccia (profondità, taglio, sponda). Criticità: centrocampo poco creativo – la costruzione offensiva dipende dagli attaccanti che arretrano. Difesa solida (Upamecano, Saliba, Koundé). Portiere Maignan. Variabili: gestione infortuni e condizione fisica dei big. Ideale per scout, giornalisti e tifosi.
- Analisi della lineup francese
Mappa mentale per l’analisi della formazione francese ai Mondiali 2026. Punti chiave: attacco stellare guidato da Mbappé, con triplice minaccia (profondità, taglio, sponda). Criticità: centrocampo poco creativo – la costruzione offensiva dipende dagli attaccanti che arretrano. Difesa solida (Upamecano, Saliba, Koundé). Portiere Maignan. Variabili: gestione infortuni e condizione fisica dei big. Ideale per scout, giornalisti e tifosi.
- Recommended to you
- Outline






Machine learning algorithm and nomogram construction for prediction of diabetic retinopathy in patients with type 2 diabetes
- 29

